RAG 知识库:增强式信息检索生成技术解析
2025年3月13日 · 2338 字 · 5 分钟

1. 什么是 RAG 知识库?
RAG(Retrieval Augmented Generation,增强式信息检索生成)知识库是一种基于文本向量化和大语言模型的自然语言处理应用。其核心目标是通过结合信息检索与生成技术,克服传统语言模型的上下文限制,从海量数据中精准定位与用户提问最相关的内容,并利用大语言模型对信息进行整合与优化,输出准确且信息丰富的回答。
与传统搜索引擎相比,RAG 知识库的优势在于其更紧密的语义结合能力以及更高的本地化部署灵活性。传统搜索引擎依赖于字符匹配(模式匹配)来查找结果,而 RAG 则是基于语义(即句子的含义)进行匹配。这种基于语义的检索方式能够更准确地理解用户意图,并结合语言模型的归纳能力,将零散的信息整合为通顺、贴切的答案。此外,RAG 知识库支持本地部署,能够帮助用户高效管理和检索本地文件,这是传统网络搜索引擎(如百度)无法实现的。
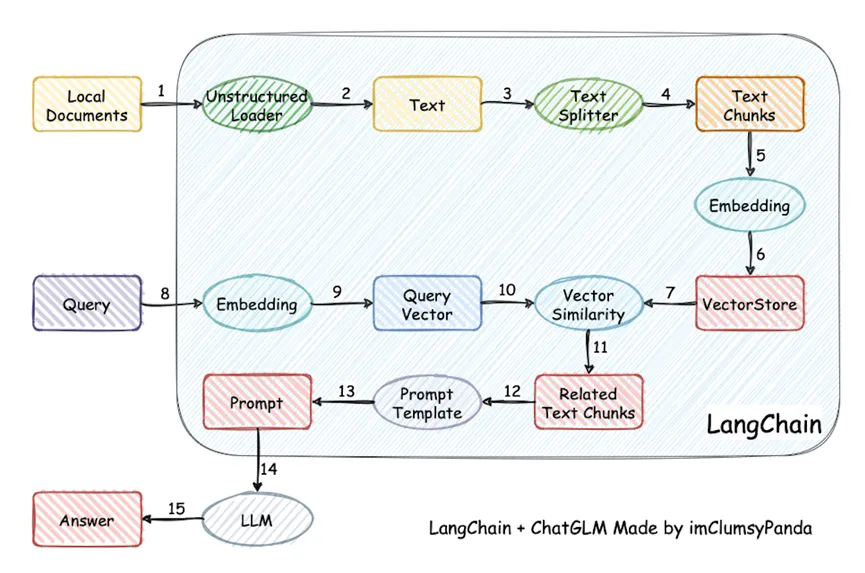
2. RAG 知识库的工作原理
RAG 知识库的核心架构分为三个模块:
-
文本拆分模块
该模块负责对输入的长文本进行分块处理,将大段文本拆分为多个短段落。这种分块方式降低了后续内容定位的难度,同时提高了检索效率。 -
词嵌入(Embedding)模块
词嵌入模块将离散且不定长的文本转化为连续且定长的向量,并将这些向量存储到向量数据库中以支持增删查改等操作。通过词嵌入技术,语义相近的文本会被映射到向量空间中相近的位置,从而实现基于语义的相似度计算。 -
大语言模型模块(LLM)
该模块负责对检索到的信息进行归纳、整理和格式化,最终生成用户易于理解的高质量回答。
词嵌入模块的深入解析
词嵌入模块的核心任务是将文本转化为向量,并通过向量之间的相似度来衡量语义的相似性。传统的字符匹配方法在某些场景下存在局限性。例如:
- 句子“我是一个开心的人”和“我是一条开心的狗”在字符和语法上非常相似,但语义却完全不同。
- 句子“你说的对”和“啊对对对,你说的对”虽然在字面上相似,但语气和含义却截然相反。
词嵌入模型通过捕捉字与字之间的关系(即“注意力机制”),将文本转化为高维向量。语义相近的文本在向量空间中的距离也会更近,从而能够更准确地衡量语义相似度。常用的相似度度量方法包括余弦相似度和欧式距离等。
然而,词嵌入模型并非万能。其效果受限于训练数据和模型结构,可能无法完全处理隐喻、反讽等复杂语言现象。例如,某些模型可能难以区分“你说的对”和“啊对对对,你说的对”之间的语义差异。
需要注意的是,上述介绍仅为 RAG 知识库的基本原理。实际应用中还涉及许多优化环节,例如源数据的清洗与整理、知识脑图的构建等。
3. 如何选择或搭建 RAG 知识库?
目前,RAG 知识库的应用主要分为两类:
-
企业级集成产品
例如 FastGPT,这类产品通常提供开箱即用的服务,用户只需登录即可使用。其优点是操作简单、体验优化,适合快速上手的场景;缺点是价格较高,且需要联网使用。 -
开源本地化部署项目
例如 ragflow,这类项目允许用户将软件部署到本地,既可以选择调用云端 API,也可以完全在本地完成计算。其优点是无需联网,速度和安全性更有保障;缺点是需要一定的技术能力,且对硬件配置有一定要求。
对于有兴趣深入了解人工智能技术的开发者来说,RAG 知识库是一个非常好的入门项目。其实现难度适中,能够帮助开发者快速掌握自然语言处理的核心技术。
4. 动手实践:代码实现一个简单的 RAG 知识库
接下来,我们将通过一个简单的示例,演示如何构建一个基于云端 Embedding 和 LLM 模型的 RAG 知识库。
需求场景
假设我们要开一家餐馆,并使用 Deepseek 生成了一本包含 40 道原创菜谱的文档。我们希望将这些菜谱导入 RAG 知识库,并通过提问获取相关菜谱。
实现步骤
-
生成菜谱文档
创建[recipe_book.md]文件,包含 40 道菜的制作方法。 -
导入并拆分菜谱
将菜谱文档导入 RAG 知识库,知识库将其拆分为 40 个独立的文本块,例如[菜谱0, 菜谱1, ..., 菜谱39]。 -
生成词嵌入向量
使用 Embedding 模型将 40 个文本块转化为 40 个高维定长向量[a0, a1, a2, ..., a39],并将这些向量与原始文本一一对应存储。 -
处理用户提问
当用户提问“我想喝南瓜汤,找篇菜谱给我”时,使用 Embedding 模型将问题转化为向量b0。 -
检索最相似向量
在向量[a0, a1, a2, ..., a39]中查找与b0最相似的向量。假设结果为a6,则对应文本为菜谱6。 -
生成最终回答
将用户问题与检索到的菜谱6一起输入大语言模型,通过提示词(Prompt)控制输出格式,例如:“问题是(xxxx),请基于(xxxxxx)回答,不要自由发挥。”
通过以上步骤,我们成功构建了一个简单的 RAG 知识库,并实现了基于语义的菜谱检索与生成功能。
实现上述功能的代码如下:
import re
import numpy as np
from openai import OpenAI
import json
import os
class APIClient:
def __init__(self, config_file):
"""
初始化 API 客户端,从配置文件中加载必要信息。
"""
with open(config_file, 'r', encoding='utf-8') as f:
self.config = json.load(f)
self.client = OpenAI(
api_key=self.config["api_key"],
base_url=self.config["base_url"]
)
self.provider = "openai"
def get_embeddings(self, texts):
"""
获取文本的嵌入向量。
"""
response = self.client.embeddings.create(
input=texts,
model=self.config["embedding_model"]
)
return [item.embedding for item in response.data]
def generate_response(self, prompt, context):
"""
生成回答。
"""
response = self.client.chat.completions.create(
model=self.config["llm_model"],
messages=[
{"role": "system", "content": "你是个人助理,请根据我给的内容,解答我的问题,不要原创。"},
{"role": "user", "content": f"{prompt}\n\n 。相关知识如下,请根据下列相关知识回答,不要自由发挥: {context}"}
],
max_tokens=2000
)
return response.choices[0].message.content
def save_embeddings_to_json(embeddings, file_path):
with open(file_path, 'w', encoding='utf-8') as f:
json.dump(embeddings, f, ensure_ascii=False, indent=4)
def load_embeddings_from_json(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
embeddings = json.load(f)
return embeddings
def read_file(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
return content
def split_text_into_chunks(text, chunk_size=2000):
sentences = re.split(r'(?<=[。!?])', text)
chunks = []
current_chunk = ""
for sentence in sentences:
if len(current_chunk) + len(sentence) <= chunk_size:
current_chunk += sentence
else:
chunks.append(current_chunk)
current_chunk = sentence
if current_chunk:
chunks.append(current_chunk)
return chunks
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
def main(api_provider):
# 根据选择的 API 提供商加载配置文件
if api_provider == "openai":
config_file = "openai_config.json"
elif api_provider == "ali":
config_file = "ali_config.json"
else:
raise ValueError("Unsupported API provider.")
# 初始化 API 客户端
api_client = APIClient(config_file)
file_path = 'sub.md'
text = read_file(file_path)
chunks = split_text_into_chunks(text)
print(f"len of chunks {len(chunks)}, last {chunks[-1]}")
embeddings_file = 'embeddings.json'
if os.path.exists(embeddings_file):
print(f"文件 {embeddings_file} 存在")
embeddings = load_embeddings_from_json(embeddings_file)
else:
print(f"文件 {embeddings_file} 不存在")
embeddings = api_client.get_embeddings(chunks)
save_embeddings_to_json(embeddings, 'embeddings.json')
query = "我想喝南瓜汤,找篇菜谱给我"
query_embedding = api_client.get_embeddings([query])[0]
similarities = [cosine_similarity(query_embedding, chunk_embedding) for chunk_embedding in embeddings]
most_similar_chunk_index = np.argmax(similarities)
context = chunks[most_similar_chunk_index]
print(f"\n\n\n\n相关内容: {context}\n\n\n\n")
response = api_client.generate_response(query, context)
print("\n\nGenerated Response:\n\n")
print(response)
if __name__ == "__main__":
# 选择 API 提供商
api_provider = "ali" # 可选 "openai" 或 "ali"
main(api_provider)